Processing hundreds of millions records got much easier
SQL 2012 or higher - Processing hundreds of millions records can be done in less than an hour.
Processing hundreds of millions of records requires a different strategy and the implementation should be different compared to smaller tables with only several millions of records.
Call us for Free Consultation for Remote DBA services at our SQL Consulting Firm at: 732-536-4765
Say you have 800 millions of records in a table and you need to delete 200 million. Obviously you can use this code:
The problem is that you are running one big transaction and the log file will grow tremendously. The process can take a long time. It also depends on the speed of your server as well.
Convert MS Access to Web Based. Call us for Free Consultation at: 732-536-4765
The solution is to use small batches and process 1 to several millions of records at the time. This way the log file stays small and whenever a new process starts, the new batch will reuse the same log file space and it will not grow. Before I used the batch process technique, in one time I had 250 GB log file when I tried to split the Address field.
If I need to move 250 millions of records from one database to another the batch processing technique is a winner. Under my server it would take 30 minutes and 41 seconds, and also can track down the time per each batch. This way I will be able to predict when the entire process is finished. Another advantage when using small batch is if you need to Cancel the process from whatever reason then it takes immediately or several seconds to recover. (Depends on your server speed).
Check our Custom Software Development Services.
I basically use this technique even for a small change that I may do in a table. Say you need to add an Identity field and you have a table with 250 millions of records. That simple code:
will take at least 7 hours to process.
Copy the whole table to an empty one will be much faster as demonstrated below. Another example for saving time is if you need to add a computed field as a Persisted one, it took us more than a day without using the batch technique for a table of 250 millions of records. The time it takes also depends of the complexity of the computed field. A persisted computed field was part of the empty table where data was inserted and that did not change the speed of the below process.
Another advantage for using ms sql batch processing code is when you have an error. It is very helpful to debug ms sql table. In my case it could be a truncate error when trying to fix data from one field to another. By looking at the Batch Process table you can see the last processed batch range and you can go right into that range and inspect the data. You know it is the last batch since the code will stop working after the error occurred. When process hundreds of millions records sometimes bad data could cause a truncate issue.
The technique below requires that you have a clustered index on the PK, and this way 1 million records takes to process from 8 to 30 seconds compare to 10 minutes without a clustered index. But even without the clustered index working with batches reduces the processing time by far. To split an Address to Street Number and Street Name without a clustered index took about 8 hours and before it took days to process. For that process an UPDATE was used. For the below process even though I used the ORDER BY First and Last, the clustered index on Users_PK was sufficient for the entire process and no other indexes were needed. Again in other cases you may need to have additional indexes.
Whenever the above code is running you can run the below code and see the status of the process:
In the below image the time difference between rows 7 and 8 was 8 seconds, and in rows 1 to 2 it was 7 seconds, and so far 6,957,786 records were processed, and that batch was 994804 records. You can see the range of PK that was processed as well.
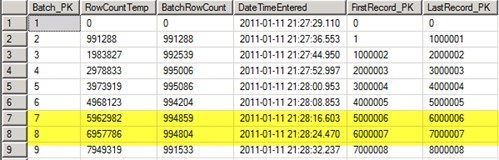
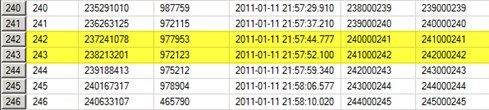
Looking further towards the end of this process, then the difference between rows 242 to 243 is 8 seconds as well. As you see you can have a very good estimate of the time for the entire process.

I started to develop custom software since 1985 while using dBase III from Aston Tate. From there I moved to FoxBase and to FoxPro and ended up working with Visual FoxPro until Microsoft stopped supporting that great engine. With the Visual FoxPro, I developed the VisualRep which is Report and Query Engine. We are also a dot net development company, and one of our projects is a web scrapping from different web sites. We are Alpha AnyWhere developers, and the Avis Car Rental company trusted us with their contract management software that we developed with the Alpha Five software Engine.
Comments