Remove Duplicate Records in SQL
In MS SQL 2005 and later editions, a much better way has been provided to remove duplicate records smartly, while having full control of which records to remove. It can be accomplished by using the ROW_NUMBER() which will return a number of row within a partition of a result set. With this code:
You can have a partition on something like Email or SSN or a combination of several fields like: First, Last, Street Number, Street Name and City.
Call us for Free Consultation for Remote DBA services at our SQL Consulting Firm at: 732-536-4765
The idea is to perform data cleansing while removing records where you can control any aspect of it. What's even better is the ability to combine different pieces of data from different records into one record while the rest of the records for that partition (group) are removed with no data being lost. Duplicate data is a problem that exists in many databases and the purpose of removing duplicate records is to improve productivity and increase the performance of your database. The below article will discuss the technique of how to remove duplicate records - rows in MSSQL database.
Check our Convert Access To Web Services.
Let's create some sample data:
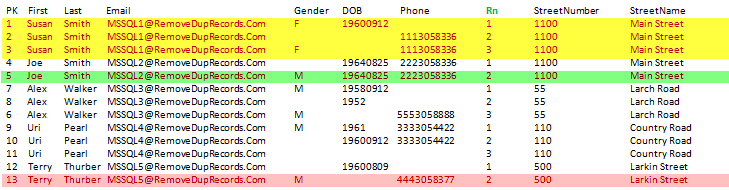
In the above, the Email works as a partition and has a unique value to allow us to create a group of records on that field and also control the order of how the records will show up. In the data below Susan Smith with the record that has the value of Rn = 2 and Rn=3 are considered as duplicate records and should be deleted.
In actuality the only difference compared to the original data that was created in the temp table named: TableWithDups is the additional column named: Rn. Every record in the Rn that is greater than 1 is considered as a duplicate one. Adding the ORDER BY on different fields can change the way the records will show up as Rn=1. See Sample 1 below to get the idea:
Sample 1:
When running the below code as Common Table Expression (CTE) flexibility is increased as shown below and a WHERE clause is added as WHERE Rn = 1. As a side note using the CTE is considered as a temporary result. The CTE can be self-referenced multiple times in the same query. It is similar to a derived table but much more flexible.
Here is the data as shown below in Sample 2 after running the above code:
Sample 2:

As you see in the above in Sample 2, all duplicate records that have Rn > 1 do not show up anymore. But if you look closely we lost some data that could have been combined in the record with Rn=1. We can increase the partition by adding more fields to make sure there are no duplicate addresses, but that would not change the fact that some data will be lost.
The real power of the above technique is that we can combine several values from different duplicate records in the record that gets the value of Rn=1. Let's examine closely what we have above. If you look at Sample 2 then Joe Smith and Terry Thurber lost the data in the Gender column. Looking at Sample 1 under PK= 5, the Gender is M for Joe and also PK = 13 which is Terry Thurber. The same problem exists also for the Phone number as well. The following code will take care of this problem and incorporate all required pieces of data in one record.
Sample 3:

The below is the continuation of the above data.

Using the MAX(Phone) with the partition technique on each field that we don't want to lose data, will make sure to get the data in the row that Rn=1. Having this code on the Phone MAX(Phone) OVER (PARTITION BY Email) AS Phone_Updated and create a new column to show the new data near the original column helps to analyze the data to make sure everything works fine.
In the above code we make sure that no data is lost while we remove all duplicate records. When all partitions are handled then we create ROW_NUMBER() OVER (PARTITION…) on all combinations of fields that create a unique partition. We also ORDER each field that was part of the MAX() as DESC. Order the field as DESC is crucial and is part of the technique of merging all data from different rows into one row of the same partition. In addition, I added code around the DOB (Date of Birth) since in some cases it has only 0 value and clearing the DOB to nothing is a better data for me.
In sample 3 all fields such as: Gender_Updated, DOB_Updated and Phone_Updated are filled with data while all other duplicate records were removed. In Sample 3 Joe Smith and Terry Thurber did not lose any data compared to Sample 2. In addition, the idea is to copy all records to a different table while leaving the original data as UN touched for a backup.
The DOB is a VARCHAR (10), since when import data it is always a character based field that comes in many different formats. For additional info on that matter please see this article at: data cleansing and manipulating date format.
Check our Custom Software Development Services.
Conclusions:
==========
Once you have found your duplicate records, you face the problem of merging multiple records into one without losing any data. Some of the problems you might face when merging records could be that it has a phone or another record could have an email address and you cannot afford to remove these duplicate records when you are taking the risk of losing some important data. The duplicate record remover that was discussed above covers all of these points and provides a solution that safely removes duplicate records from your database. In addition, to use the code above the Sample 3 data is when you know for sure that you may have fields with empty data; otherwise simply use the code above the Sample 2 data.

I started to develop custom software since 1985 while using dBase III from Aston Tate. From there I moved to FoxBase and to FoxPro and ended up working with Visual FoxPro until Microsoft stopped supporting that great engine. With the Visual FoxPro, I developed the VisualRep which is Report and Query Engine. We are also a dot net development company, and one of our projects is a web scrapping from different web sites. We are Alpha AnyWhere developers, and the Avis Car Rental company trusted us with their contract management software that we developed with the Alpha Five software Engine.
Comments